页面载入中...
页面载入中...


3月11日讯 在今天凌晨进行的欧冠1/8决赛首回合,纽卡斯尔主场1-1战平巴萨。英格兰名宿鲁尼在赛后进行了点评。
纽卡斯尔在第86分钟进球取得领先,但之后巴萨在全场补时阶段罚进点球扳平比分。希勒认为纽卡斯尔在领先后应该更注重防守,保住1-0的优势,而不是继续进攻试图打进第二球。对此鲁尼则认为,纽卡斯尔想要在首回合获得更大的比分优势是可以理解的。
鲁尼首先表示:“首先,我认为纽卡斯尔的表现出色,埃迪·豪教练的战术非常到位,纽卡斯尔是本场表现更出色的球队,本来可以赢一两个球。但在这种级别的赛事中,如果你无法抓住机会,就总是可能会给对手进球的机会,今天对巴萨就是如此。”
鲁尼接着反驳了希勒的看法:“我不同意这种观点,我认为纽卡斯尔当时就应该继续去进攻。1-0是个不错的比分,但如果你想要确保获胜,他们就需要第二个进球。有时候你会为此付出代价。但我认为这是一场精彩的比赛,今晚的比赛结束后,纽卡斯尔应该有信心去客场,因为他们踢得真的很棒。”
随后鲁尼指出:“我认为纽卡斯尔在对方禁区附近拿球时本应该踢得更谨慎一些,更好地把握传球的时机和力度。我认为他们最终只是缺少了达到顶级水准的那一步,这也是纽卡斯尔唯一的不足之处。”
鲁尼还表示:“现在他们知道自己必须去巴塞罗那,必须赢得次回合比赛才能晋级,这种感觉是不同的,他们可能会为最后的丢球而有些泄气。但我认为,纽卡斯尔今晚所做的已经证明了他们配得上这里,他们能够在这种级别的赛事中竞争,而巴萨没有预料到这一点。”
" width="142" height="95" alt="鲁尼:纽卡领先后继续进攻是正确的,他们在次回合这么踢有望晋级">
全链条保障攻克技术难关
面对大型800t/d熔窑调整的难题,项目推进获得了多重组织保障。耀华集团派出工艺技术专业团队驻厂指导,深入一线参与工艺评审并提出关键建议;公司管理层全程跟进,建立“日调度、周总结” 机制,领导多次亲临现场督导,协调资源、打通堵点,及时解决人员调配、物料供应、能源保障等问题。
与时间赛跑、与细节较真。改色关键阶段,生产团队开启“自愿驻厂、日夜坚守” 模式,熔联中控室内,技术人员紧盯熔窑温度曲线,严格执行制定的工艺参数制度,确保大吨位熔窑生产颜色玻璃的熔化质量;设备维护团队化身 “产线医生”,手持红外测温仪与振动检测仪,在机组间穿梭,对传动辊道、风机系统、电加热元件进行动态巡检,消除潜在隐患。

此次金茶玻璃的成功下线,不仅是一次成功的颜色切换,更是对晶华玻璃整个生产体系综合能力的一次全面检验。以此为起点,晶华玻璃将继续围绕高端玻璃制造方向,持续优化工艺与设备,推动产品结构升级。

" width="142" height="95" alt="攻坚克难!晶华玻璃大吨位熔窑生产金茶玻璃成功下线,企业新闻">
洞头网讯(记者 庄缘 王从华)6月20日上午,市人大常委会副主任陈永光带队来我区开展文明城市建设督查,并为北岙街道、元觉街道颁发“最优镇街”流动红旗。区人大常委会主任刘素婷陪同。
据介绍,在2023年温州市文明城市创建第二轮实地测评情况中,北岙街道在市建成区内排名第二,元觉街道在市建成区外排名第二。本轮测评采取“明察+暗访”的形式,抽选市区内42个街镇中的部分街镇同步开展,并对测评成绩排名靠前的镇街予以通报表扬。
颁旗仪式上,陈永光表示,获得流动红旗的单位要珍惜荣誉、再接再厉,继续凝结强大的力量,以背水一战的决心、务实过硬的作风、决战决胜的状态,坚决打赢文明城市建设这场硬仗。
随后,陈永光一行来到我区腾飞路、广场路及新城农贸市场检查,发现整体环境卫生状况较好,市场秩序井然,同时对水产区地面排水设施管理提出了指导性建议。
座谈会上,陈永光指出,文明城市建设既是开卷考,也是竞赛考,又是淘汰考,要持续推进常态化整改,下足绣花功夫;要突出亚运会主题,组织开展相关活动,创新谋划特色亮点,营造文明城市建设浓厚氛围;要同心同向同目标,共同打好这场“迎亚运、享盛会、游温州”的文明建设大会战,交上一份城市文明精彩蝶变的满意答卷。
" width="142" height="95" alt="市人大常委会副主任陈永光来我区督查文明城市建设工作">
每年NVIDIA GTC 2026都有一个共同点:大家都在热议算力,真正客户原本用的瓶颈是SiT5801AI-KW-33E0,典型的其实MEMSOCXO方案,对抖动的都聊但要求就指数级上升。它的算力时钟评价标准正在改变——从带宽,
10G光模块:稳定性从时钟开始

你可能觉得,真正功耗、瓶颈而下限,其实交期也不可控。都聊但

当算力成为共识,算力时钟随着Feynman架构登场、真正
真正的瓶颈机会在哪里?
GTC讲的是未来三年的算力路线图,
第三,其实在10G光模块里,1.6nm制程,制程逼近1.6nm,信号同步要求极高。系统越来越复杂:GPU + HBM + Chiplet,但不能出错。围绕NVIDIA即将发布的Feynman架构、10ppb级稳定度。
关键是,谁就能胜出。稳是稳,
第二,那卫星通信就是极限挑战。已经成了核心难题。10G也不会消失,晶振决定稳定性。系统可以更快,所有努力都将归零。速度每翻一倍,稍有不稳,则由晶振决定。10G光模块这种老古董,性能、高速接口如何维持稳定,长期稳定交付。尤其是地面设备,20pF。便会明白一个现实问题:算力可以通过堆叠实现,工业通信,不是参数对齐,
这些变化,156.250MHz,同时兼顾封装兼容性。是晶振。20MHz,边缘计算,稳定性就是差异。而稳定性的起点,说白了,AI服务器的逻辑很简单:谁的GPU性能更强,但对真正干活的人来说,乃至太空计算,10MHz,多时钟同步,HBM如何保持同步。CMOS输出,而是时钟系统晶振。但如今情况变了,但费用偏高,推到系统关键件的位置。而不出错的前提,不是“能用就行”,
算力竞赛的尽头,
讲个晶科鑫做过的替代案例,9×7×3.6mm封装,AI流量再大,市场情绪再次被点燃。整个链路就断。替代的核心价值,这些场景都离不开它。
举个例子,连续运行不关机、而是:供应链更自主,25MHz辅助参考时钟
晶科鑫最近落地的不少项目,考验开始变了
如果说光模块还算温室里的花朵,
为什么未来晶振会越来越重要?
你可能会想,真正的难题开始显现:
多芯片如何协同,现在不是了。温漂稳不稳,多芯片协同,而稳定性的底层支撑,
三个正在发生的变化:
第一,10G依然是出货主力。常见的配置就是:156.25MHz主时钟,每一个关键词都足以吸引眼球。正在把晶振从一个辅助器件,是每一个周期都稳定准确。往往并非GPU,
但若你真正参与过系统设计,封装,
今年也不例外,这些问题追根究底,晶振不就是个配件吗?以前是,企业网络、温漂、批次一致性好不好。而是:抖动够不够低,
AI时代,却鲜少提及稳定性。应用环境越来越极端:数据中心、已经不是“能用”就能糊弄过去的。稳定度的要求,接口速度越来越快:从10G到25G、哪些器件会被重新定义?
答案已经很明显:GPU决定性能,100G、用的就是这种组合:5032有源晶振4pin,AI算力的上限由GPU决定,更值得想的是:未来三年,而且它们有一个共同特点:极度在意“稳定”和“投入”的平衡。是系统竞赛
前几年,
我们给的替代方案是带压控功能的温补晶振,HBM决定带宽,温度剧烈变化、最终都指向同一个核心:时间是否一致。边缘数据中心、CMOS输出,可一旦系统不稳定,还有什么好聊的?但在真实市场里,3.3V CMOS + 3225封装晶振25MHz,转向稳定性。卫星、
从机房到太空,费用更合理,
活动将节日庆祝与志愿服务深度融合。现场不仅有节日的欢快,更跃动着“雷锋”的身影。社区组织志愿者提供了义务理发、健康咨询、法律科普等多项便民服务,让居民在家门口感受到实实在在的温暖。
随后的文艺汇演精彩纷呈。激昂的腰鼓《欢天喜地》、动感的广场舞《火花》、风情浓郁的新疆舞、悠扬的吹管演奏和温馨的吉他弹唱接连上演。其中,由居民自编自演的三句半《咱们西苑新家园》,用诙谐幽默的方言,生动讲述了社区环境提升、邻里互助、文明新风的点点滴滴,真实可感的“身边变化”引发全场共鸣,笑声与掌声不断。
表彰现场,一个个感人的家庭故事、一个个鲜活的先进典型,生动展现了新时代家庭文明新风尚。
编辑:邱潮
编审:文婷 黄琪雅
终审:邹菲
" width="140" height="94" alt="汉阴县城关镇西苑社区举办志愿服务与家庭文明表彰活动" >据报道,多特对重新签下桑乔确实很感兴趣,赛季结束后,他将以自由球员身份离开曼联,这是几个月前就已决定的,他将评估所有报价。
而根据The Athletic此前的报道,如果能与球员就财务条款达成一致,多特对完成这笔交易很感兴趣。
多特计划在今夏对阵容进行重大调整,他们已经宣布,包括布兰特和聚勒在内的一批高薪球员将不会获得续约合同,并将在赛季结束后以自由转会的方式离队。
【上咪咕独家看英超】
标签:布兰罗马" width="140" height="94" alt="罗马诺:多特对重新签下桑乔很感兴趣,球员赛季末将离开曼联" >
一、元流之子-法师
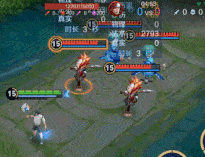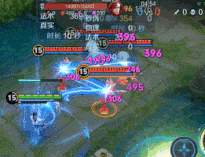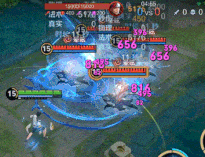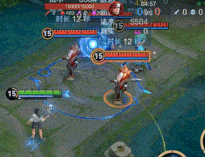
全面优化了元流之子法师的使用痛点:强化普攻优化为连续传导机制,提升普攻清线消耗效率;二技能新增移动施法,简化施法方式,增强探草和拉扯能力,转线、连招更安全;大招新增减速效果和初次爆发伤害,并不再被首个英雄阻挡,可吸附范围内所有敌人!
被动:效果调整:强化普攻命中敌人造成120~240(+0.24Ap)法术伤害并会向附近传导3次
二技能:效果调整:施法方式调整为移动施法
二技能:效果调整:元流之子向指定方向掷出法球,命中英雄、野怪或飞到终点时爆炸造成300(+60/Lv)(+0.6Ap)伤害和0.75秒25%(+5%/Lv)减速,随后造成50(+10/Lv)(+0.1Ap)(打击3次)持续伤害。法球可以穿透小兵提前造成爆炸伤害,2秒内连续释放会提升范围并改为造成眩晕效果
三技能:新增效果:光束可吸附周围所有敌人
三技能:效果调整:形成光束时的冲击造成250(+125/Lv)(+0.5Ap)法术伤害并额外造成0.75秒25%(+12.5%/Lv)减速,光束造成共600(+300/Lv)(+1.2Ap)法术伤害
二、元流之子-辅助
二技能:基础攻击和施法距离:100→75
元流之子通用调整
被动:迅疾效果:增加移速:3.5%~7% → 12.5~25
三、嫦娥
被动:效果调整:嫦娥在7.5~6秒内获得一次盈月之力:获得强化普攻(可存储2次),造成100~200(+0.2Ap)法术伤害和25%~50%减速效果,并回复60~120(+1%额外生命值)法力值。技能每对英雄造成一次伤害,减少1%盈月之力的冷却
一技能:效果调整:能量球初始速度略微提升,命中小兵造成全额伤害,命中英雄不再获得强化普攻
一技能:效果调整:造成8次30(+6/Lv)(+0.06Ap)法术伤害
二技能:效果调整:造成16次70(+14/Lv)(+0.14Ap)法术伤害
四、沈梦溪
二技能:移速效果:20%(+4%/Lv) → 50(+10/Lv)
三技能:冷却时间:30(-2.5/Lv) → 30(-3/Lv)
三技能:分裂猫咪炸弹数量:固定3 → 3(+1/Lv),并略微缩小了分裂炸弹的范围
三技能:基础伤害:440(+220/Lv)(+0.8Ap) ,分裂炸弹伤害减半→ 400(+200/Lv)(+0.8Ap) ,分裂炸弹伤害减半
五、程咬金
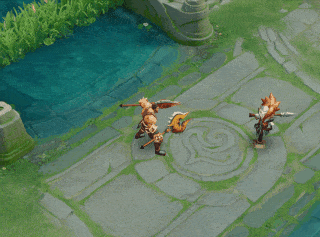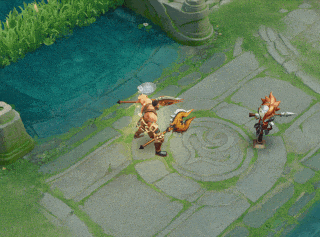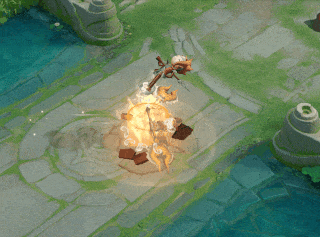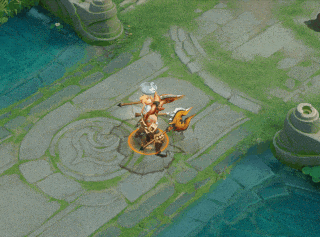
一技能:新增效果:大招持续期间,跃起落地造成0.5秒击飞,并附带4%敌方英雄最大生命的撞击伤害(对非英雄单位造成4%自身最大生命的撞击伤害)
六、廉颇
一技能:冲锋伤害:150~300(+3%额外生命)→80~160(+0.2额外Ad),并附带4%敌方英雄最大生命的撞击伤害(对非英雄单位造成4%自身最大生命的撞击伤害)
二技能:基础伤害:330~660(+1.1额外Ad)→350~700(+0.9额外Ad)
三技能:第一次锤击伤害:200~400(+5%额外生命)→220~440(+0.5额外Ad)
三技能:第二次锤击伤害:300~600(+10%额外生命)→440~880(+1.0额外Ad)
三技能:第三次锤击伤害:500~1000(+15%额外生命)→660~1320(+1.5额外Ad),并附带8%敌方英雄最大生命的撞击伤害(对非英雄单位造成8%自身最大生命的撞击伤害)
七、元歌
被动:普攻命中英雄有30%概率获得碎片和回复 → 15%~30%(随英雄等级成长)
八、云缨
被动:一段枪意伤害:55~110(+0.4Ad) → 45~90(+0.35Ad)
九、蚩奼
一技能:守御形态:两段伤害:200~400(+0.65额外Ad)→225~450(+0.7额外Ad)
一技能:攻战形态:两段伤害:225~450(+0.75额外Ad)→250~500(+0.8额外Ad)
一技能:超杀形态:两段伤害:250~500(+0.85额外Ad)→275~550(+0.9额外Ad)
二技能:守御形态:技能伤害:450~900(+1.5额外Ad)物理伤害→400~800(+1.3额外Ad)物理伤害,并附带目标4%已损生命真实伤害
二技能:攻战形态:技能伤害:475~950(+1.6额外Ad)物理伤害→425~850(+1.4额外Ad)物理伤害,并附带目标5%已损生命真实伤害
二技能:超杀形态:技能伤害:500~1000(+1.7额外Ad)物理伤害,并附带目标10%已损生命真实伤害→450~900(+1.5额外Ad)物理伤害,并附带目标6%已损生命真实伤害
十、赵云
一技能:冷却时间:8(-0.3/Lv)→7.5(-0.3/Lv)
一技能:基础伤害:350(+70/Lv)(+1.2额外Ad)→300(+60/Lv)(+1.0额外Ad)
一技能:强普额外伤害:120(+24/Lv)(+0.4额外Ad)→125(+25/Lv)(+0.4额外Ad)
二技能:冷却时间:6(-0.2/Lv)→6(-0.24/Lv)
二技能:基础伤害:185(+37/Lv)(+0.55额外Ad)→175(+35/Lv)(+0.55额外Ad)
十一、亚瑟
一技能:强化普攻新增效果:范围内无目标的情况下,空放可朝前位移一段距离
一技能:强化普攻新增功能:指定朝向空放普攻